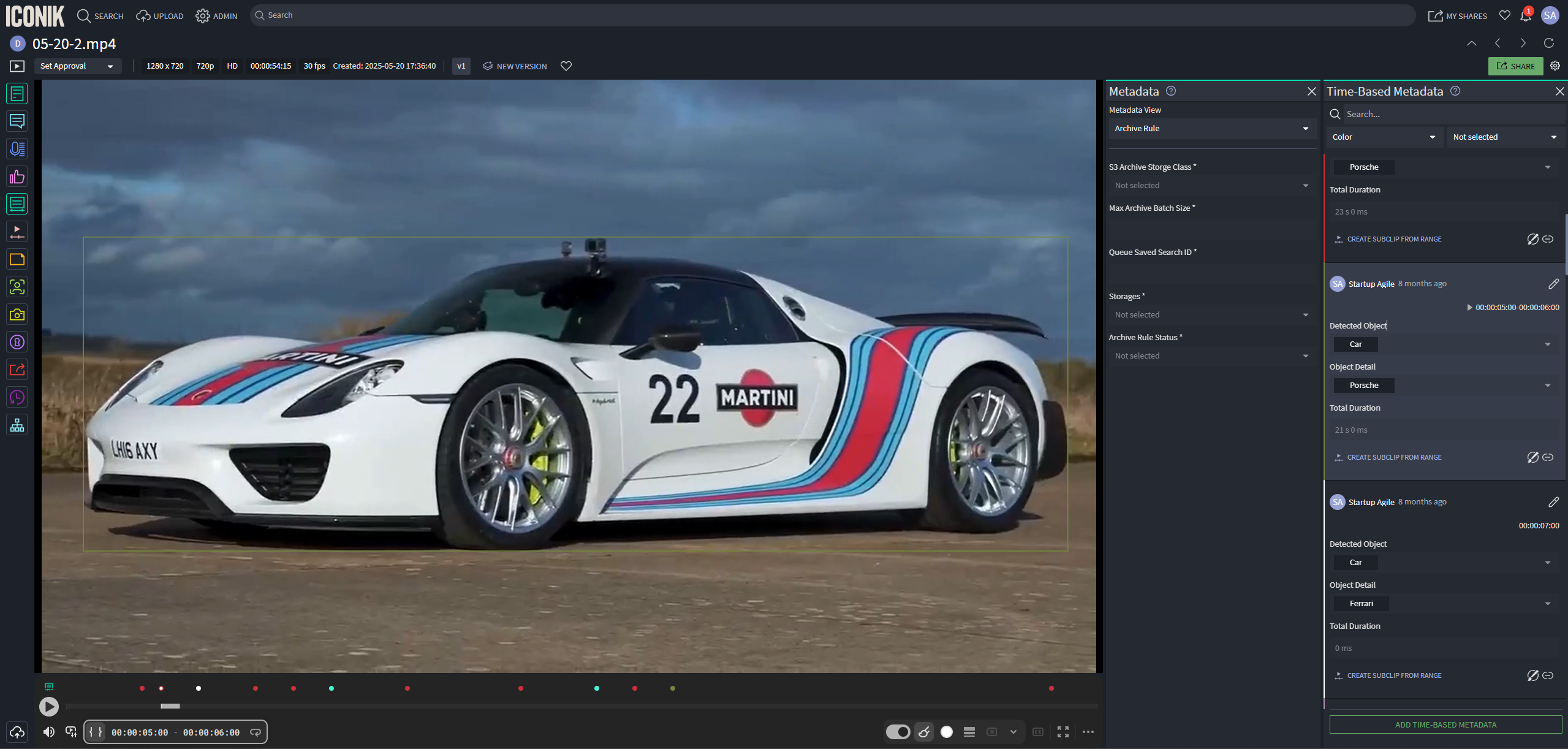
The client runs an enterprise media operation with terabytes of video footage living across Media Asset Management (MAM) platforms like Iconik and CATDV. Most of that footage was effectively invisible — searchable only by filename and whatever a human had manually logged, which for the bulk of the archive was nothing.
Post-production teams couldn't find the footage they already owned. Manual logging doesn't scale to terabytes of uploads, so a large share of the archive went unused. The system had to identify what was actually in each video and make it discoverable — without adding work for editors, and without bottlenecking on a single synchronous pipeline.